Public Health Data Tabulation with {gtsummary}
Introduction
Acknowledgements

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License (CC BY-SA4.0).
Creators of original presentation
Daniel D. Sjoberg



Checklist
Install recent R release
Current version 4.2.3Install RStudio
I am on version 2022.07.1+554 Install packages
Ensure you can knit Rmarkdown files
{gtsummary} overview
- Create tabular summaries with sensible defaults but highly customizable
- Types of summaries:
- “Table 1”-types
- Cross-tabulation
- Regression models
- Survival data
- Survey data
- Custom tables
- Report statistics from {gtsummary} tables inline in R Markdown
- Stack and/or merge any table type
- Use themes to standardize across tables
- Choose from different print engines
Example Dataset
The “steps.xlsx” data set is available for downloading under Dataset Tab
This is a randomly sampled subset of WHO STEPS Survey conducted for NCD risk factor surveillance
It consists of selected variables from all three steps of the survey.
library(gtsummary)
library(tidyverse)
library(rio)
library(here)
df <- import(here("datasets", "steps.xlsx"))
head(df) |> gt::gt()| Gender | Age | Age_Group | Education | SBP | DBP | BMI | LDL | Smoking | Physical_Inactivity | Raised_BP | District | WSTEP3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Women | 60 | 59-69 | Illiterate | 116.6667 | 77.00000 | 16.10928 | 49.2 | No | No | No | Balaghat | 8398.779 |
| Men | 67 | 59-69 | Higher Secondary + | 166.6667 | 97.33333 | 25.29558 | 74.6 | No | No | Yes | Satna | 6269.137 |
| Men | 18 | 18-30 | Higher Secondary + | 127.6667 | 79.33333 | 22.17560 | 53.8 | No | No | No | Ratlam | 30503.785 |
| Women | 67 | 59-69 | Illiterate | 106.3333 | 67.00000 | 17.28791 | 42.0 | No | Yes | No | Dindori | 8898.991 |
| Men | 38 | 30-44 | Secondary | 114.0000 | 74.00000 | 18.14509 | 28.0 | Yes | No | No | Damoh | 16746.247 |
| Women | 58 | 44-59 | Illiterate | 158.3333 | 87.33333 | 26.18594 | 95.6 | No | No | Yes | Ratlam | 15545.019 |
Example Dataset
This presentation will use a variables from the dataset to demonstrate different tables.
| Variable |
|---|
| Gender |
| Age |
| Age_Group |
| Education |
| SBP |
| DBP |
| BMI |
| LDL |
| Smoking |
| Physical_Inactivity |
| Raised_BP |
| District |
| WSTEP3 |
tbl_summary()
Basic tbl_summary()
| Characteristic | N = 3,0001 |
|---|---|
| Gender | |
| Men | 1,039 (35%) |
| Women | 1,961 (65%) |
| Age | 40 (30, 51) |
| Age_Group | |
| 18-30 | 691 (23%) |
| 30-44 | 1,097 (37%) |
| 44-59 | 799 (27%) |
| 59-69 | 413 (14%) |
| Education | |
| Higher Secondary + | 832 (28%) |
| Illiterate | 1,162 (39%) |
| Primary | 493 (16%) |
| Secondary | 513 (17%) |
| SBP | 125 (114, 138) |
| Unknown | 26 |
| DBP | 78 (71, 85) |
| Unknown | 26 |
| BMI | 20.2 (18.0, 23.3) |
| Unknown | 78 |
| LDL | 57 (42, 75) |
| Smoking | 275 (9.2%) |
| Physical_Inactivity | 594 (20%) |
| Raised_BP | 825 (28%) |
| District | |
| Balaghat | 357 (12%) |
| Bhopal | 438 (15%) |
| Damoh | 218 (7.3%) |
| Dhar | 429 (14%) |
| Dindori | 141 (4.7%) |
| Hoshangabad | 235 (7.8%) |
| Ratlam | 281 (9.4%) |
| Satna | 452 (15%) |
| Sheopur | 115 (3.8%) |
| Shivpuri | 334 (11%) |
| WSTEP3 | 16,031 (14,218, 17,604) |
| 1 n (%); Median (IQR) | |
Four types of summaries:
continuous,continuous2,categorical, anddichotomousStatistics are
median (IQR)for continuous,n (%)for categorical/dichotomousVariables coded
0/1,TRUE/FALSE,Yes/Notreated as dichotomousLists
NAvalues under “Unknown”Label attributes are printed automatically
Customize tbl_summary() output
| Characteristic | No, N = 2,1751 | Yes, N = 8251 |
|---|---|---|
| Gender | ||
| Men | 744 (34%) | 295 (36%) |
| Women | 1,431 (66%) | 530 (64%) |
| Age_Group | ||
| 18-30 | 636 (29%) | 55 (6.7%) |
| 30-44 | 868 (40%) | 229 (28%) |
| 44-59 | 495 (23%) | 304 (37%) |
| 59-69 | 176 (8.1%) | 237 (29%) |
| BMI | 19.7 (17.7, 22.4) | 21.8 (18.9, 25.3) |
| Unknown | 70 | 8 |
| 1 n (%); Median (IQR) | ||
by: specify a column variable for cross-tabulation
Customize tbl_summary() output
| Characteristic | No, N = 2,1751 | Yes, N = 8251 |
|---|---|---|
| Gender | ||
| Men | 744 (34%) | 295 (36%) |
| Women | 1,431 (66%) | 530 (64%) |
| Age_Group | ||
| 18-30 | 636 (29%) | 55 (6.7%) |
| 30-44 | 868 (40%) | 229 (28%) |
| 44-59 | 495 (23%) | 304 (37%) |
| 59-69 | 176 (8.1%) | 237 (29%) |
| BMI | ||
| Median (IQR) | 19.7 (17.7, 22.4) | 21.8 (18.9, 25.3) |
| Unknown | 70 | 8 |
| 1 n (%) | ||
by: specify a column variable for cross-tabulationtype: specify the summary type
Customize tbl_summary() output
| Characteristic | No, N = 2,1751 | Yes, N = 8251 |
|---|---|---|
| Gender | ||
| Men | 744 / 2,175 (34%) | 295 / 825 (36%) |
| Women | 1,431 / 2,175 (66%) | 530 / 825 (64%) |
| Age_Group | ||
| 18-30 | 636 (29%) | 55 (6.7%) |
| 30-44 | 868 (40%) | 229 (28%) |
| 44-59 | 495 (23%) | 304 (37%) |
| 59-69 | 176 (8.1%) | 237 (29%) |
| BMI | ||
| Mean (SD) | 20.5 (3.9) | 22.5 (4.8) |
| Range | 11.9, 47.8 | 13.5, 47.8 |
| Unknown | 70 | 8 |
| 1 n / N (%); n (%) | ||
by: specify a column variable for cross-tabulationtype: specify the summary typestatistic: customize the reported statistics
Customize tbl_summary() output
| Characteristic | No, N = 2,1751 | Yes, N = 8251 |
|---|---|---|
| Gender | ||
| Men | 744 / 2,175 (34%) | 295 / 825 (36%) |
| Women | 1,431 / 2,175 (66%) | 530 / 825 (64%) |
| Age Group | ||
| 18-30 | 636 (29%) | 55 (6.7%) |
| 30-44 | 868 (40%) | 229 (28%) |
| 44-59 | 495 (23%) | 304 (37%) |
| 59-69 | 176 (8.1%) | 237 (29%) |
| BMI | ||
| Mean (SD) | 20.5 (3.9) | 22.5 (4.8) |
| Range | 11.9, 47.8 | 13.5, 47.8 |
| Unknown | 70 | 8 |
| 1 n / N (%); n (%) | ||
by: specify a column variable for cross-tabulationtype: specify the summary typestatistic: customize the reported statistics
label: change or customize variable labels
Customize tbl_summary() output
| Characteristic | No, N = 2,1751 | Yes, N = 8251 |
|---|---|---|
| Gender | ||
| Men | 744 / 2,175.0 (34%) | 295 / 825.0 (36%) |
| Women | 1,431 / 2,175.0 (66%) | 530 / 825.0 (64%) |
| Age Group | ||
| 18-30 | 636 (29.2%) | 55 (6.7%) |
| 30-44 | 868 (39.9%) | 229 (27.8%) |
| 44-59 | 495 (22.8%) | 304 (36.8%) |
| 59-69 | 176 (8.1%) | 237 (28.7%) |
| BMI | ||
| Mean (SD) | 20.5 (3.9) | 22.5 (4.8) |
| Range | 11.9, 47.8 | 13.5, 47.8 |
| Unknown | 70 | 8 |
| 1 n / N (%); n (%) | ||
by: specify a column variable for cross-tabulationtype: specify the summary typestatistic: customize the reported statistics
label: change or customize variable labelsdigits: specify the number of decimal places for rounding
{gtsummary} + formulas
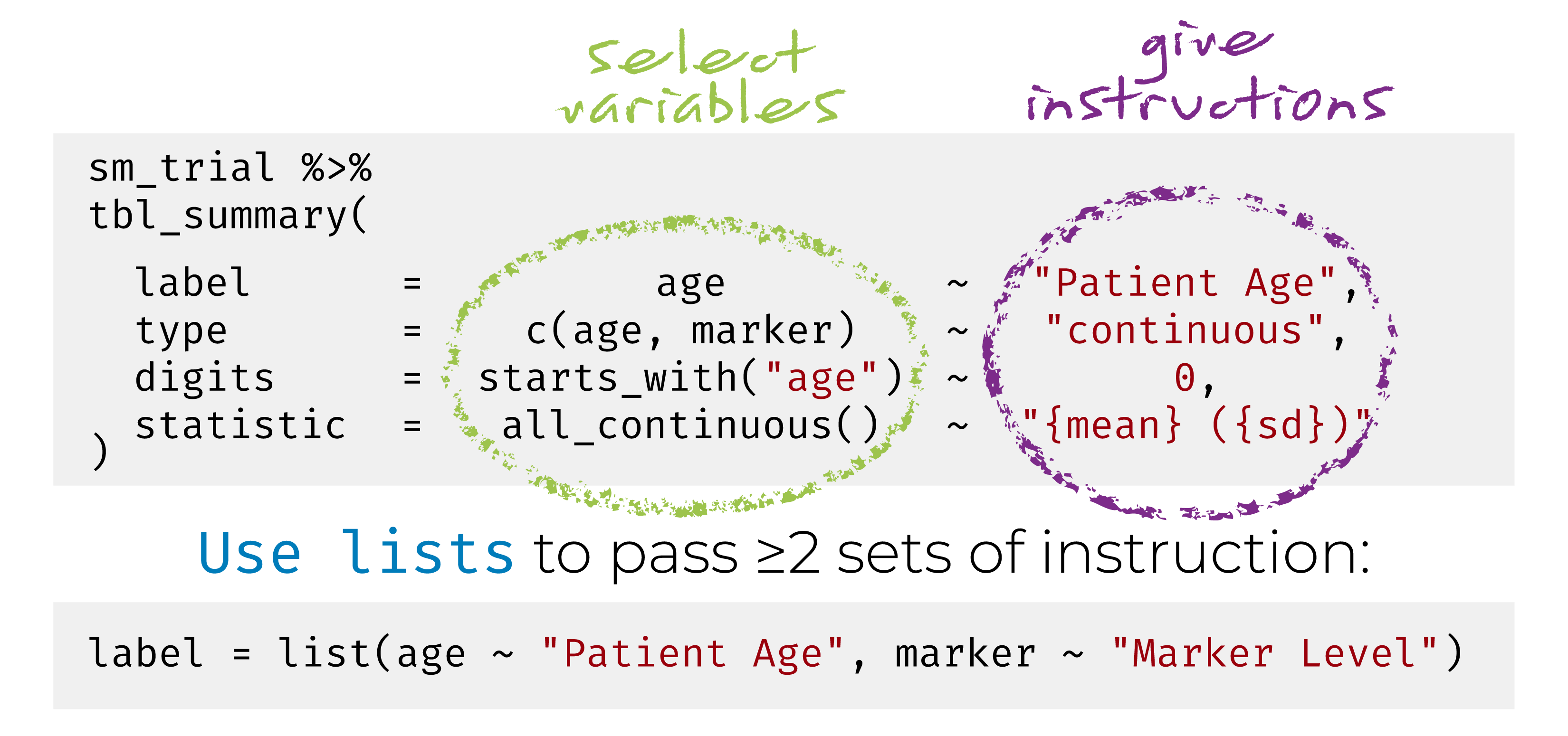
Named list are OK too! label = list(age = "Patient Age")
Add-on functions in {gtsummary}
tbl_summary() objects can also be updated using related functions.
add_*()add additional column of statistics or information, e.g. p-values, q-values, overall statistics, treatment differences, N obs., and moremodify_*()modify table headers, spanning headers, footnotes, and morebold_*()/italicize_*()style labels, variable levels, significant p-values
Update tbl_summary() with add_*()
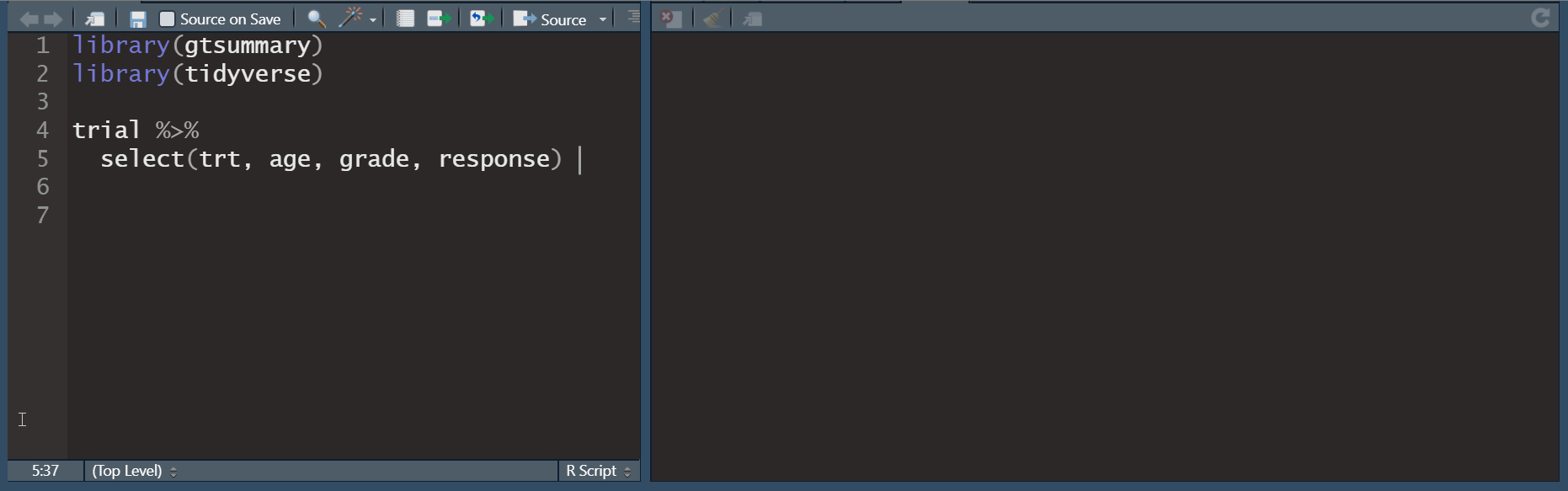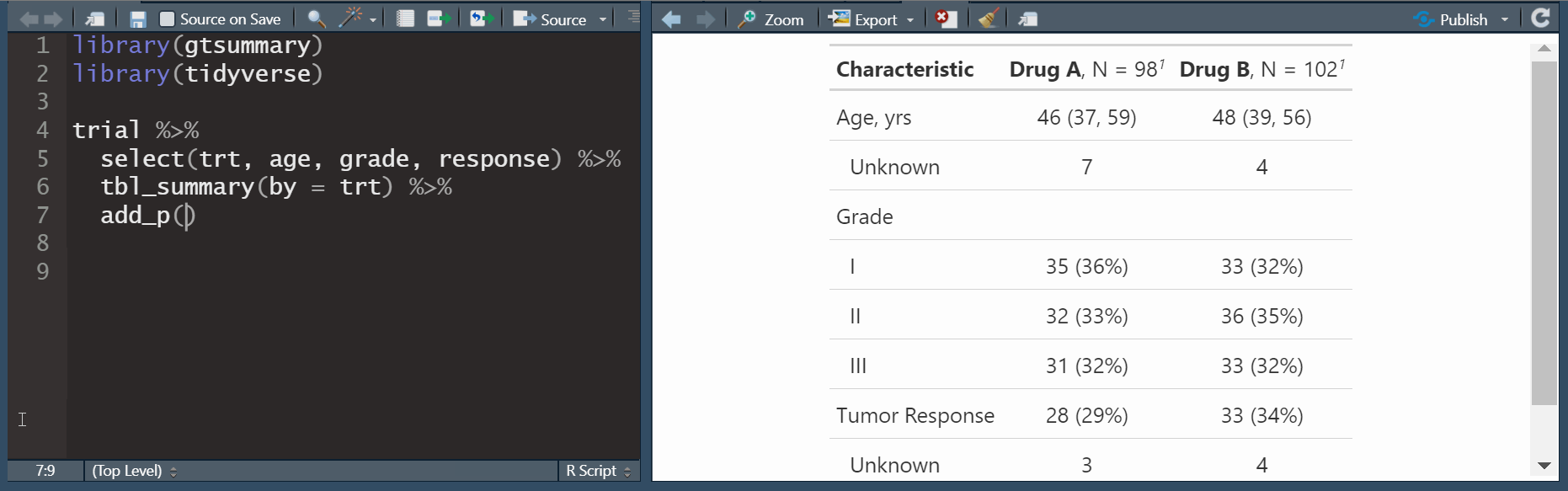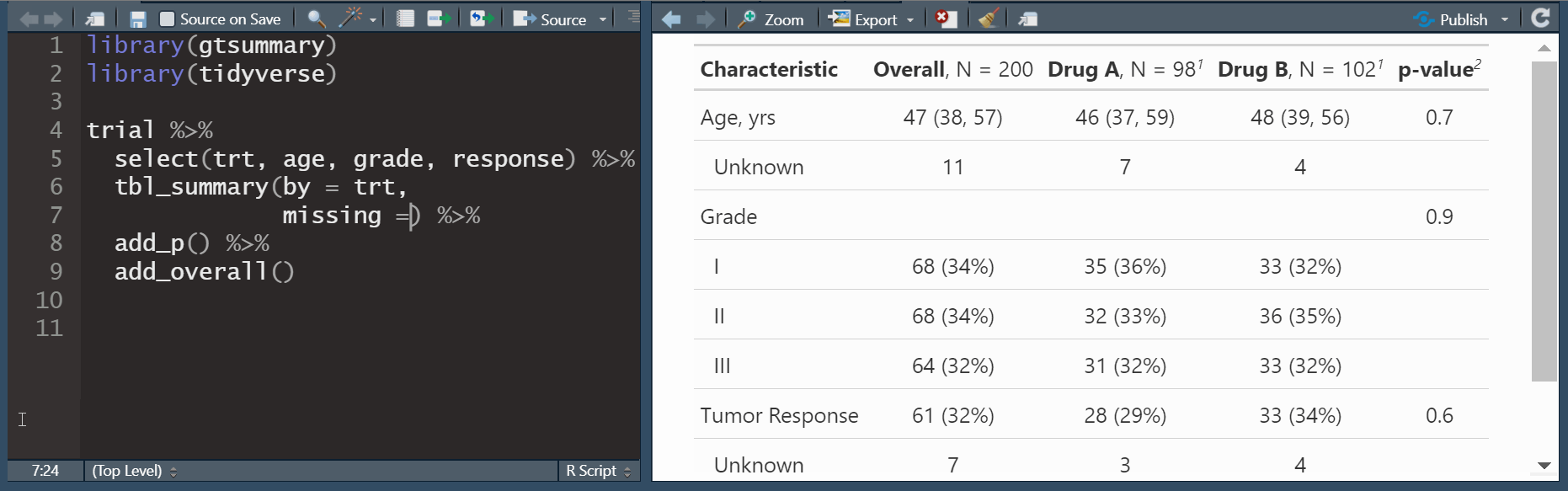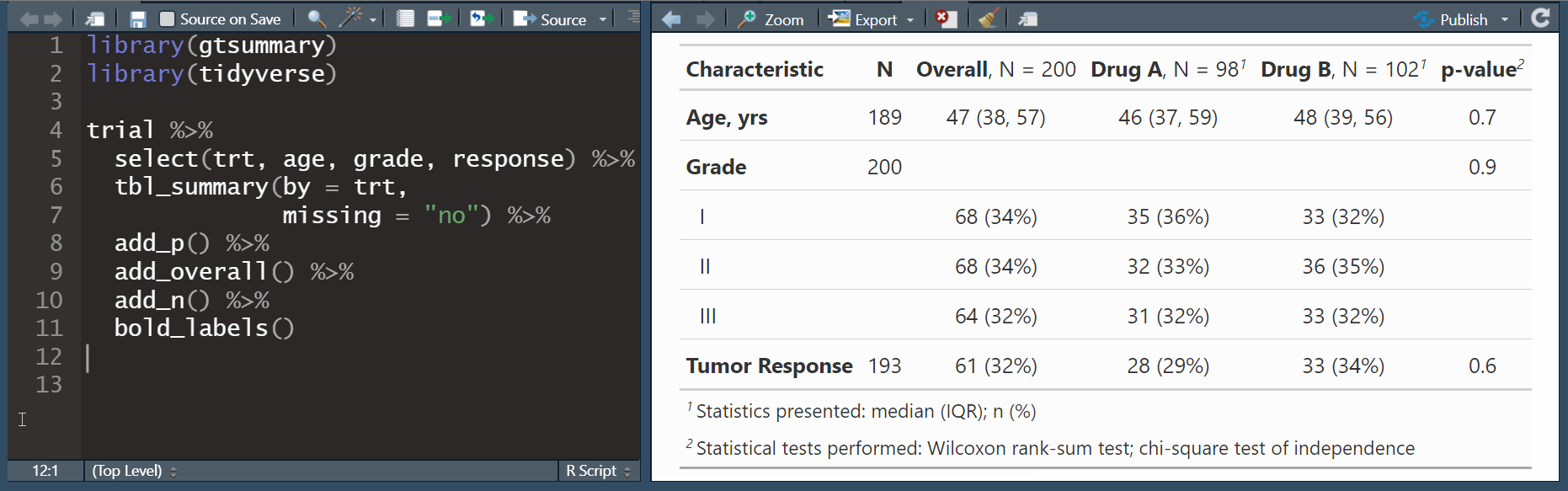
| Characteristic | No, N = 2,1751 | Yes, N = 8251 | p-value2 |
|---|---|---|---|
| Gender | 0.4 | ||
| Men | 744 (34%) | 295 (36%) | |
| Women | 1,431 (66%) | 530 (64%) | |
| Age | 35 (28, 46) | 50 (40, 60) | <0.001 |
| Age_Group | <0.001 | ||
| 18-30 | 636 (29%) | 55 (6.7%) | |
| 30-44 | 868 (40%) | 229 (28%) | |
| 44-59 | 495 (23%) | 304 (37%) | |
| 59-69 | 176 (8.1%) | 237 (29%) | |
| Education | <0.001 | ||
| Higher Secondary + | 610 (28%) | 222 (27%) | |
| Illiterate | 790 (36%) | 372 (45%) | |
| Primary | 372 (17%) | 121 (15%) | |
| Secondary | 403 (19%) | 110 (13%) | |
| SBP | 119 (111, 127) | 149 (142, 161) | <0.001 |
| Unknown | 26 | 0 | |
| DBP | 75 (69, 80) | 91 (83, 97) | <0.001 |
| Unknown | 26 | 0 | |
| BMI | 19.7 (17.7, 22.4) | 21.8 (18.9, 25.3) | <0.001 |
| Unknown | 70 | 8 | |
| LDL | 55 (42, 72) | 61 (43, 82) | <0.001 |
| Smoking | 187 (8.6%) | 88 (11%) | 0.080 |
| Physical_Inactivity | 426 (20%) | 168 (20%) | 0.6 |
| District | <0.001 | ||
| Balaghat | 236 (11%) | 121 (15%) | |
| Bhopal | 303 (14%) | 135 (16%) | |
| Damoh | 168 (7.7%) | 50 (6.1%) | |
| Dhar | 292 (13%) | 137 (17%) | |
| Dindori | 103 (4.7%) | 38 (4.6%) | |
| Hoshangabad | 182 (8.4%) | 53 (6.4%) | |
| Ratlam | 218 (10%) | 63 (7.6%) | |
| Satna | 356 (16%) | 96 (12%) | |
| Sheopur | 82 (3.8%) | 33 (4.0%) | |
| Shivpuri | 235 (11%) | 99 (12%) | |
| WSTEP3 | 16,469 (14,982, 22,945) | 14,644 (9,505, 16,230) | <0.001 |
| 1 n (%); Median (IQR) | |||
| 2 Pearson’s Chi-squared test; Wilcoxon rank sum test | |||
add_p(): adds a column of p-values
Update tbl_summary() with add_*()
| Characteristic | Overall, N = 3,0001 | No, N = 2,1751 | Yes, N = 8251 |
|---|---|---|---|
| Gender | |||
| Men | 1,039 (35%) | 744 (34%) | 295 (36%) |
| Women | 1,961 (65%) | 1,431 (66%) | 530 (64%) |
| Age | 40 (30, 51) | 35 (28, 46) | 50 (40, 60) |
| Age_Group | |||
| 18-30 | 691 (23%) | 636 (29%) | 55 (6.7%) |
| 30-44 | 1,097 (37%) | 868 (40%) | 229 (28%) |
| 44-59 | 799 (27%) | 495 (23%) | 304 (37%) |
| 59-69 | 413 (14%) | 176 (8.1%) | 237 (29%) |
| Education | |||
| Higher Secondary + | 832 (28%) | 610 (28%) | 222 (27%) |
| Illiterate | 1,162 (39%) | 790 (36%) | 372 (45%) |
| Primary | 493 (16%) | 372 (17%) | 121 (15%) |
| Secondary | 513 (17%) | 403 (19%) | 110 (13%) |
| SBP | 125 (114, 138) | 119 (111, 127) | 149 (142, 161) |
| DBP | 78 (71, 85) | 75 (69, 80) | 91 (83, 97) |
| BMI | 20.2 (18.0, 23.3) | 19.7 (17.7, 22.4) | 21.8 (18.9, 25.3) |
| LDL | 57 (42, 75) | 55 (42, 72) | 61 (43, 82) |
| Smoking | 275 (9.2%) | 187 (8.6%) | 88 (11%) |
| Physical_Inactivity | 594 (20%) | 426 (20%) | 168 (20%) |
| District | |||
| Balaghat | 357 (12%) | 236 (11%) | 121 (15%) |
| Bhopal | 438 (15%) | 303 (14%) | 135 (16%) |
| Damoh | 218 (7.3%) | 168 (7.7%) | 50 (6.1%) |
| Dhar | 429 (14%) | 292 (13%) | 137 (17%) |
| Dindori | 141 (4.7%) | 103 (4.7%) | 38 (4.6%) |
| Hoshangabad | 235 (7.8%) | 182 (8.4%) | 53 (6.4%) |
| Ratlam | 281 (9.4%) | 218 (10%) | 63 (7.6%) |
| Satna | 452 (15%) | 356 (16%) | 96 (12%) |
| Sheopur | 115 (3.8%) | 82 (3.8%) | 33 (4.0%) |
| Shivpuri | 334 (11%) | 235 (11%) | 99 (12%) |
| WSTEP3 | 16,031 (14,218, 17,604) | 16,469 (14,982, 22,945) | 14,644 (9,505, 16,230) |
| 1 n (%); Median (IQR) | |||
add_overall(): adds a column of overall statistics
Update tbl_summary() with add_*()
| Characteristic | N | Overall, N = 3,0001 | No, N = 2,1751 | Yes, N = 8251 |
|---|---|---|---|---|
| Gender | 3,000 | |||
| Men | 1,039 (35%) | 744 (34%) | 295 (36%) | |
| Women | 1,961 (65%) | 1,431 (66%) | 530 (64%) | |
| Age | 3,000 | 40 (30, 51) | 35 (28, 46) | 50 (40, 60) |
| Age_Group | 3,000 | |||
| 18-30 | 691 (23%) | 636 (29%) | 55 (6.7%) | |
| 30-44 | 1,097 (37%) | 868 (40%) | 229 (28%) | |
| 44-59 | 799 (27%) | 495 (23%) | 304 (37%) | |
| 59-69 | 413 (14%) | 176 (8.1%) | 237 (29%) | |
| Education | 3,000 | |||
| Higher Secondary + | 832 (28%) | 610 (28%) | 222 (27%) | |
| Illiterate | 1,162 (39%) | 790 (36%) | 372 (45%) | |
| Primary | 493 (16%) | 372 (17%) | 121 (15%) | |
| Secondary | 513 (17%) | 403 (19%) | 110 (13%) | |
| SBP | 2,974 | 125 (114, 138) | 119 (111, 127) | 149 (142, 161) |
| DBP | 2,974 | 78 (71, 85) | 75 (69, 80) | 91 (83, 97) |
| BMI | 2,922 | 20.2 (18.0, 23.3) | 19.7 (17.7, 22.4) | 21.8 (18.9, 25.3) |
| LDL | 3,000 | 57 (42, 75) | 55 (42, 72) | 61 (43, 82) |
| Smoking | 3,000 | 275 (9.2%) | 187 (8.6%) | 88 (11%) |
| Physical_Inactivity | 3,000 | 594 (20%) | 426 (20%) | 168 (20%) |
| District | 3,000 | |||
| Balaghat | 357 (12%) | 236 (11%) | 121 (15%) | |
| Bhopal | 438 (15%) | 303 (14%) | 135 (16%) | |
| Damoh | 218 (7.3%) | 168 (7.7%) | 50 (6.1%) | |
| Dhar | 429 (14%) | 292 (13%) | 137 (17%) | |
| Dindori | 141 (4.7%) | 103 (4.7%) | 38 (4.6%) | |
| Hoshangabad | 235 (7.8%) | 182 (8.4%) | 53 (6.4%) | |
| Ratlam | 281 (9.4%) | 218 (10%) | 63 (7.6%) | |
| Satna | 452 (15%) | 356 (16%) | 96 (12%) | |
| Sheopur | 115 (3.8%) | 82 (3.8%) | 33 (4.0%) | |
| Shivpuri | 334 (11%) | 235 (11%) | 99 (12%) | |
| WSTEP3 | 3,000 | 16,031 (14,218, 17,604) | 16,469 (14,982, 22,945) | 14,644 (9,505, 16,230) |
| 1 n (%); Median (IQR) | ||||
add_overall(): adds a column of overall statisticsadd_n(): adds a column with the sample size
Update tbl_summary() with add_*()
| Characteristic | N | Overall, N = 3,000 | No, N = 2,175 | Yes, N = 825 |
|---|---|---|---|---|
| Gender, No. (%) | 3,000 | |||
| Men | 1,039 (35%) | 744 (34%) | 295 (36%) | |
| Women | 1,961 (65%) | 1,431 (66%) | 530 (64%) | |
| Age, Median (IQR) | 3,000 | 40 (30, 51) | 35 (28, 46) | 50 (40, 60) |
| Age_Group, No. (%) | 3,000 | |||
| 18-30 | 691 (23%) | 636 (29%) | 55 (6.7%) | |
| 30-44 | 1,097 (37%) | 868 (40%) | 229 (28%) | |
| 44-59 | 799 (27%) | 495 (23%) | 304 (37%) | |
| 59-69 | 413 (14%) | 176 (8.1%) | 237 (29%) | |
| Education, No. (%) | 3,000 | |||
| Higher Secondary + | 832 (28%) | 610 (28%) | 222 (27%) | |
| Illiterate | 1,162 (39%) | 790 (36%) | 372 (45%) | |
| Primary | 493 (16%) | 372 (17%) | 121 (15%) | |
| Secondary | 513 (17%) | 403 (19%) | 110 (13%) | |
| SBP, Median (IQR) | 2,974 | 125 (114, 138) | 119 (111, 127) | 149 (142, 161) |
| DBP, Median (IQR) | 2,974 | 78 (71, 85) | 75 (69, 80) | 91 (83, 97) |
| BMI, Median (IQR) | 2,922 | 20.2 (18.0, 23.3) | 19.7 (17.7, 22.4) | 21.8 (18.9, 25.3) |
| LDL, Median (IQR) | 3,000 | 57 (42, 75) | 55 (42, 72) | 61 (43, 82) |
| Smoking, No. (%) | 3,000 | 275 (9.2%) | 187 (8.6%) | 88 (11%) |
| Physical_Inactivity, No. (%) | 3,000 | 594 (20%) | 426 (20%) | 168 (20%) |
| District, No. (%) | 3,000 | |||
| Balaghat | 357 (12%) | 236 (11%) | 121 (15%) | |
| Bhopal | 438 (15%) | 303 (14%) | 135 (16%) | |
| Damoh | 218 (7.3%) | 168 (7.7%) | 50 (6.1%) | |
| Dhar | 429 (14%) | 292 (13%) | 137 (17%) | |
| Dindori | 141 (4.7%) | 103 (4.7%) | 38 (4.6%) | |
| Hoshangabad | 235 (7.8%) | 182 (8.4%) | 53 (6.4%) | |
| Ratlam | 281 (9.4%) | 218 (10%) | 63 (7.6%) | |
| Satna | 452 (15%) | 356 (16%) | 96 (12%) | |
| Sheopur | 115 (3.8%) | 82 (3.8%) | 33 (4.0%) | |
| Shivpuri | 334 (11%) | 235 (11%) | 99 (12%) | |
| WSTEP3, Median (IQR) | 3,000 | 16,031 (14,218, 17,604) | 16,469 (14,982, 22,945) | 14,644 (9,505, 16,230) |
add_overall(): adds a column of overall statisticsadd_n(): adds a column with the sample sizeadd_stat_label(): adds a description of the reported statistic
Update with bold_*()/italicize_*()
| Characteristic | No, N = 2,1751 | Yes, N = 8251 | p-value2 |
|---|---|---|---|
| Gender | 0.4 | ||
| Men | 744 (34%) | 295 (36%) | |
| Women | 1,431 (66%) | 530 (64%) | |
| Age | 35 (28, 46) | 50 (40, 60) | <0.001 |
| Age_Group | <0.001 | ||
| 18-30 | 636 (29%) | 55 (6.7%) | |
| 30-44 | 868 (40%) | 229 (28%) | |
| 44-59 | 495 (23%) | 304 (37%) | |
| 59-69 | 176 (8.1%) | 237 (29%) | |
| Education | <0.001 | ||
| Higher Secondary + | 610 (28%) | 222 (27%) | |
| Illiterate | 790 (36%) | 372 (45%) | |
| Primary | 372 (17%) | 121 (15%) | |
| Secondary | 403 (19%) | 110 (13%) | |
| SBP | 119 (111, 127) | 149 (142, 161) | <0.001 |
| Unknown | 26 | 0 | |
| DBP | 75 (69, 80) | 91 (83, 97) | <0.001 |
| Unknown | 26 | 0 | |
| BMI | 19.7 (17.7, 22.4) | 21.8 (18.9, 25.3) | <0.001 |
| Unknown | 70 | 8 | |
| LDL | 55 (42, 72) | 61 (43, 82) | <0.001 |
| Smoking | 187 (8.6%) | 88 (11%) | 0.080 |
| Physical_Inactivity | 426 (20%) | 168 (20%) | 0.6 |
| District | <0.001 | ||
| Balaghat | 236 (11%) | 121 (15%) | |
| Bhopal | 303 (14%) | 135 (16%) | |
| Damoh | 168 (7.7%) | 50 (6.1%) | |
| Dhar | 292 (13%) | 137 (17%) | |
| Dindori | 103 (4.7%) | 38 (4.6%) | |
| Hoshangabad | 182 (8.4%) | 53 (6.4%) | |
| Ratlam | 218 (10%) | 63 (7.6%) | |
| Satna | 356 (16%) | 96 (12%) | |
| Sheopur | 82 (3.8%) | 33 (4.0%) | |
| Shivpuri | 235 (11%) | 99 (12%) | |
| WSTEP3 | 16,469 (14,982, 22,945) | 14,644 (9,505, 16,230) | <0.001 |
| 1 n (%); Median (IQR) | |||
| 2 Pearson’s Chi-squared test; Wilcoxon rank sum test | |||
bold_labels(): bold the variable labelsitalicize_levels(): italicize the variable levelsbold_p(): bold p-values according a specified threshold
Update tbl_summary() with modify_*()
| Characteristic | BP Status | |
|---|---|---|
| No raised BP1 | Raised BP1 | |
| Gender | ||
| Men | 744 (34%) | 295 (36%) |
| Women | 1,431 (66%) | 530 (64%) |
| Age | 35 (28, 46) | 50 (40, 60) |
| Age_Group | ||
| 18-30 | 636 (29%) | 55 (6.7%) |
| 30-44 | 868 (40%) | 229 (28%) |
| 44-59 | 495 (23%) | 304 (37%) |
| 59-69 | 176 (8.1%) | 237 (29%) |
| Education | ||
| Higher Secondary + | 610 (28%) | 222 (27%) |
| Illiterate | 790 (36%) | 372 (45%) |
| Primary | 372 (17%) | 121 (15%) |
| Secondary | 403 (19%) | 110 (13%) |
| SBP | 119 (111, 127) | 149 (142, 161) |
| DBP | 75 (69, 80) | 91 (83, 97) |
| BMI | 19.7 (17.7, 22.4) | 21.8 (18.9, 25.3) |
| LDL | 55 (42, 72) | 61 (43, 82) |
| Smoking | 187 (8.6%) | 88 (11%) |
| Physical_Inactivity | 426 (20%) | 168 (20%) |
| District | ||
| Balaghat | 236 (11%) | 121 (15%) |
| Bhopal | 303 (14%) | 135 (16%) |
| Damoh | 168 (7.7%) | 50 (6.1%) |
| Dhar | 292 (13%) | 137 (17%) |
| Dindori | 103 (4.7%) | 38 (4.6%) |
| Hoshangabad | 182 (8.4%) | 53 (6.4%) |
| Ratlam | 218 (10%) | 63 (7.6%) |
| Satna | 356 (16%) | 96 (12%) |
| Sheopur | 82 (3.8%) | 33 (4.0%) |
| Shivpuri | 235 (11%) | 99 (12%) |
| WSTEP3 | 16,469 (14,982, 22,945) | 14,644 (9,505, 16,230) |
| 1 median (IQR) for continuous; n (%) for categorical | ||
- Use
show_header_names()to see the internal header names available for use inmodify_header()
Column names
| Column Name | Column Header |
|---|---|
| label | Characteristic |
| stat_1 | No raised BP |
| stat_2 | Raised BP |
all_stat_cols() selects columns "stat_1" and "stat_2"
Update tbl_summary() with add_*()
df |>
select(Raised_BP, SBP, BMI, LDL, Smoking) |>
tbl_summary(
by = Raised_BP,
statistic = list(c(SBP, BMI, LDL) ~ "{mean} ({sd})",
Smoking ~ "{p}%"),
missing = "no"
) |>
add_difference()| Characteristic | No, N = 2,1751 | Yes, N = 8251 | Difference2 | 95% CI2,3 | p-value2 |
|---|---|---|---|---|---|
| SBP | 119 (11) | 153 (21) | -34 | -35, -32 | <0.001 |
| BMI | 20.5 (3.9) | 22.5 (4.8) | -2.0 | -2.4, -1.7 | <0.001 |
| LDL | 58 (28) | 64 (31) | -5.4 | -7.9, -3.0 | <0.001 |
| Smoking | 8.6% | 11% | -2.1% | -4.6%, 0.43% | 0.092 |
| 1 Mean (SD); % | |||||
| 2 Welch Two Sample t-test; Two sample test for equality of proportions | |||||
| 3 CI = Confidence Interval | |||||
add_difference(): mean and rate differences between two groups. Can also be adjusted differences
Update tbl_summary() with add_*()
Add-on functions in {gtsummary}
And many more!
See the documentation at http://www.danieldsjoberg.com/gtsummary/reference/index.html
And a detailed tbl_summary() vignette at http://www.danieldsjoberg.com/gtsummary/articles/tbl_summary.html
Cross-tabulation with tbl_cross()
tbl_cross() is a wrapper for tbl_summary() for n x m tables
| Raised_BP | ||
|---|---|---|
| No | Yes | |
| District | ||
| Balaghat | 236 (66%) | 121 (34%) |
| Bhopal | 303 (69%) | 135 (31%) |
| Damoh | 168 (77%) | 50 (23%) |
| Dhar | 292 (68%) | 137 (32%) |
| Dindori | 103 (73%) | 38 (27%) |
| Hoshangabad | 182 (77%) | 53 (23%) |
| Ratlam | 218 (78%) | 63 (22%) |
| Satna | 356 (79%) | 96 (21%) |
| Sheopur | 82 (71%) | 33 (29%) |
| Shivpuri | 235 (70%) | 99 (30%) |
| Total | 2,175 (72%) | 825 (28%) |
| Pearson’s Chi-squared test, p<0.001 | ||
Continuous Summaries with tbl_continuous()
tbl_continuous() summarizes a continuous variable by 1, 2, or more categorical variables
| Characteristic | No, N = 2,1751 | Yes, N = 8251 |
|---|---|---|
| Age_Group | ||
| 18-30 | 116 (109, 125) | 141 (134, 144) |
| 30-44 | 119 (112, 127) | 145 (140, 153) |
| 44-59 | 121 (115, 129) | 150 (142, 161) |
| 59-69 | 125 (116, 132) | 157 (147, 175) |
| Gender | ||
| Men | 122 (113, 129) | 148 (142, 160) |
| Women | 118 (111, 126) | 149 (142, 161) |
| 1 SBP: Median (IQR) | ||
Survey data with tbl_svysummary()
| Characteristic | Raised BP | p-value2 | |
|---|---|---|---|
| No, N = 39,432,9561 | Yes, N = 11,491,2761 | ||
| Age_Group | <0.001 | ||
| 18-30 | 16,646,634 (92%) | 1,445,876 (8.0%) | |
| 30-44 | 14,073,391 (79%) | 3,635,210 (21%) | |
| 44-59 | 7,322,516 (62%) | 4,524,442 (38%) | |
| 59-69 | 1,390,415 (42%) | 1,885,747 (58%) | |
| Gender | 0.9 | ||
| Men | 13,472,904 (78%) | 3,889,460 (22%) | |
| Women | 25,960,052 (77%) | 7,601,815 (23%) | |
| District | 0.001 | ||
| Balaghat | 3,785,643 (71%) | 1,533,116 (29%) | |
| Bhopal | 5,737,817 (75%) | 1,935,086 (25%) | |
| Damoh | 3,123,656 (81%) | 717,595 (19%) | |
| Dhar | 4,812,133 (72%) | 1,829,268 (28%) | |
| Dindori | 1,843,049 (78%) | 505,601 (22%) | |
| Hoshangabad | 3,468,386 (82%) | 750,387 (18%) | |
| Ratlam | 4,065,569 (81%) | 931,610 (19%) | |
| Satna | 6,266,329 (82%) | 1,414,737 (18%) | |
| Sheopur | 1,814,049 (77%) | 536,462 (23%) | |
| Shivpuri | 4,516,325 (77%) | 1,337,415 (23%) | |
| 1 n (%) | |||
| 2 chi-squared test with Rao & Scott’s second-order correction | |||
Survey data with tbl_svysummary()
survey::svydesign(
ids = ~1,
data = df,
weights = ~WSTEP3
) |>
tbl_svysummary(
by = Raised_BP,
include = c(Age_Group, Gender, District),
percent = "row",
digits = list(all_categorical() ~ 1),
statistic = list(all_categorical() ~ "{p}")
) |>
add_p() |>
modify_spanning_header(
all_stat_cols() ~ "**Raised BP**")| Characteristic | Raised BP | p-value2 | |
|---|---|---|---|
| No, N = 39,432,9561 | Yes, N = 11,491,2761 | ||
| Age_Group | <0.001 | ||
| 18-30 | 92.0 | 8.0 | |
| 30-44 | 79.5 | 20.5 | |
| 44-59 | 61.8 | 38.2 | |
| 59-69 | 42.4 | 57.6 | |
| Gender | 0.9 | ||
| Men | 77.6 | 22.4 | |
| Women | 77.3 | 22.7 | |
| District | 0.001 | ||
| Balaghat | 71.2 | 28.8 | |
| Bhopal | 74.8 | 25.2 | |
| Damoh | 81.3 | 18.7 | |
| Dhar | 72.5 | 27.5 | |
| Dindori | 78.5 | 21.5 | |
| Hoshangabad | 82.2 | 17.8 | |
| Ratlam | 81.4 | 18.6 | |
| Satna | 81.6 | 18.4 | |
| Sheopur | 77.2 | 22.8 | |
| Shivpuri | 77.2 | 22.8 | |
| 1 % | |||
| 2 chi-squared test with Rao & Scott’s second-order correction | |||
tbl_regression()
Traditional model summary()
Call: glm(formula = Raised_BP ~ Age + Smoking + BMI, family = binomial(link = “logit”), data = df)
Deviance Residuals: Min 1Q Median 3Q Max
-2.4395 -0.7723 -0.4914 0.9125 2.4430
Coefficients: Estimate Std. Error z value Pr(>|z|)
(Intercept) -6.154933 0.298385 -20.628 <2e-16 Age 0.067720 0.003669 18.460 <2e-16 SmokingYes -0.008596 0.148722 -0.058 0.954
BMI 0.104944 0.010593 9.907 <2e-16 ***
Signif. codes: 0 ‘’ 0.001 ’’ 0.01 ’’ 0.05 ‘.’ 0.1 ’ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 3463.0 on 2921 degrees of freedomResidual deviance: 2930.8 on 2918 degrees of freedom (78 observations deleted due to missingness) AIC: 2938.8
Number of Fisher Scoring iterations: 4
Looks messy and it’s not easy to digest
Basic tbl_regression()
::: {.cell output-location=‘column’}
| Characteristic | log(OR)1 | 95% CI1 | p-value |
|---|---|---|---|
| Age | 0.07 | 0.06, 0.07 | <0.001 |
| Smoking | |||
| No | — | — | |
| Yes | -0.01 | -0.30, 0.28 |
0.9 |
| BMI | 0.10 | 0.08, 0.13 | <0.001 |
| 1 OR = Odds Ratio, CI = Confidence Interval | |||
:::
Displays p-values for covariates
Shows reference levels for categorical variables
Model type recognized as logistic regression with odds ratio appearing in header
Customize tbl_regression() output
::: {.cell output-location=‘column’}
tbl_regression(
m1,
exponentiate = TRUE
) |>
add_global_p() |>
add_glance_table(
include = c(nobs,
logLik,
AIC,
BIC)
)| Characteristic | OR1 | 95% CI1 | p-value |
|---|---|---|---|
| Age | 1.07 | 1.06, 1.08 | <0.001 |
| Smoking |
0.9 |
||
| No | — | — | |
| Yes | 0.99 | 0.74, 1.32 | |
| BMI | 1.11 | 1.09, 1.13 | <0.001 |
| No. Obs. | 2,922 | ||
| Log-likelihood | -1,465 | ||
| AIC | 2,939 | ||
| BIC | 2,963 | ||
| 1 OR = Odds Ratio, CI = Confidence Interval | |||
:::
Display odds ratio estimates and confidence intervals
Add global p-values
Add various model statistics
Supported models in tbl_regression()
biglm::bigglm()biglmm::bigglm()brms::brm()cmprsk::crr()fixest::feglm()fixest::femlm()fixest::feNmlm()fixest::feols()gam::gam()geepack::geeglm()glmmTMB::glmmTMB()lavaan::lavaan()lfe::felm()
lme4::glmer.nb()lme4::glmer()lme4::lmer()logitr::logitr()MASS::glm.nb()MASS::polr()mgcv::gam()mice::miramultgee::nomLORgee()multgee::ordLORgee()nnet::multinom()ordinal::clm()ordinal::clmm()
parsnip::model_fitplm::plm()rstanarm::stan_glm()stats::aov()stats::glm()stats::lm()stats::nls()survey::svycoxph()survey::svyglm()survey::svyolr()survival::clogit()survival::coxph()survival::survreg()tidycmprsk::crr()VGAM::vglm()
Custom tidiers can be written and passed to tbl_regression() using the tidy_fun= argument.
Univariate models with tbl_uvregression()
| Characteristic | N | OR1 | 95% CI1 | p-value |
|---|---|---|---|---|
| Gender | 3,000 | |||
| Men | — | — | ||
| Women | 0.93 | 0.79, 1.11 | 0.4 | |
| Age | 3,000 | 1.07 | 1.06, 1.08 | <0.001 |
| Age_Group | 3,000 | |||
| 18-30 | — | — | ||
| 30-44 | 3.05 | 2.25, 4.20 | <0.001 | |
| 44-59 | 7.10 | 5.25, 9.77 | <0.001 | |
| 59-69 | 15.6 | 11.2, 22.0 | <0.001 | |
| Education | 3,000 | |||
| Higher Secondary + | — | — | ||
| Illiterate | 1.29 | 1.06, 1.58 | 0.010 | |
| Primary | 0.89 | 0.69, 1.15 | 0.4 | |
| Secondary | 0.75 | 0.58, 0.97 | 0.031 | |
| BMI | 2,922 | 1.12 | 1.09, 1.14 | <0.001 |
| LDL | 3,000 | 1.01 | 1.00, 1.01 | <0.001 |
| Smoking | 3,000 | |||
| No | — | — | ||
| Yes | 1.27 | 0.97, 1.65 | 0.080 | |
| Physical_Inactivity | 3,000 | |||
| No | — | — | ||
| Yes | 1.05 | 0.86, 1.28 | 0.6 | |
| 1 OR = Odds Ratio, CI = Confidence Interval | ||||
Specify model
method,method.args, and theresponsevariableArguments and helper functions like
exponentiate,bold_*(),add_global_p()can also be used withtbl_uvregression()
tbl_merge()/tbl_stack()
tbl_merge() for side-by-side tables
A univariable table:
tbl_uvreg <-
df |>
select(-District, -WSTEP3, - SBP, -DBP) |>
tbl_uvregression(
method = glm,
y = Raised_BP,
method.args =
list(family = binomial),
exponentiate = TRUE
)
tbl_uvreg| Characteristic | N | OR1 | 95% CI1 | p-value |
|---|---|---|---|---|
| Gender | 3,000 | |||
| Men | — | — | ||
| Women | 0.93 | 0.79, 1.11 | 0.4 | |
| Age | 3,000 | 1.07 | 1.06, 1.08 | <0.001 |
| Age_Group | 3,000 | |||
| 18-30 | — | — | ||
| 30-44 | 3.05 | 2.25, 4.20 | <0.001 | |
| 44-59 | 7.10 | 5.25, 9.77 | <0.001 | |
| 59-69 | 15.6 | 11.2, 22.0 | <0.001 | |
| Education | 3,000 | |||
| Higher Secondary + | — | — | ||
| Illiterate | 1.29 | 1.06, 1.58 | 0.010 | |
| Primary | 0.89 | 0.69, 1.15 | 0.4 | |
| Secondary | 0.75 | 0.58, 0.97 | 0.031 | |
| BMI | 2,922 | 1.12 | 1.09, 1.14 | <0.001 |
| LDL | 3,000 | 1.01 | 1.00, 1.01 | <0.001 |
| Smoking | 3,000 | |||
| No | — | — | ||
| Yes | 1.27 | 0.97, 1.65 | 0.080 | |
| Physical_Inactivity | 3,000 | |||
| No | — | — | ||
| Yes | 1.05 | 0.86, 1.28 | 0.6 | |
| 1 OR = Odds Ratio, CI = Confidence Interval | ||||
A multivariable table:
tbl_mvreg <-
glm(
Raised_BP ~ Age_Group + Smoking + BMI + LDL,
data = df,
family = binomial(link = "logit")
) |>
tbl_regression(
exponentiate = TRUE
) |>
add_global_p()
tbl_mvreg| Characteristic | OR1 | 95% CI1 | p-value |
|---|---|---|---|
| Age_Group | <0.001 | ||
| 18-30 | — | — | |
| 30-44 | 2.47 | 1.79, 3.44 | |
| 44-59 | 5.82 | 4.23, 8.12 | |
| 59-69 | 14.6 | 10.3, 21.0 | |
| Smoking | 0.8 | ||
| No | — | — | |
| Yes | 1.03 | 0.77, 1.38 | |
| BMI | 1.11 | 1.09, 1.13 | <0.001 |
| LDL | 1.00 | 1.00, 1.00 | 0.7 |
| 1 OR = Odds Ratio, CI = Confidence Interval | |||
tbl_merge() for side-by-side tables
| Characteristic | Univariable | Multivariable | |||||
|---|---|---|---|---|---|---|---|
| N | OR1 | 95% CI1 | p-value | OR1 | 95% CI1 | p-value | |
| Gender | 3,000 | ||||||
| Men | — | — | |||||
| Women | 0.93 | 0.79, 1.11 | 0.4 | ||||
| Age | 3,000 | 1.07 | 1.06, 1.08 | <0.001 | |||
| Age_Group | 3,000 | <0.001 | |||||
| 18-30 | — | — | — | — | |||
| 30-44 | 3.05 | 2.25, 4.20 | <0.001 | 2.47 | 1.79, 3.44 | ||
| 44-59 | 7.10 | 5.25, 9.77 | <0.001 | 5.82 | 4.23, 8.12 | ||
| 59-69 | 15.6 | 11.2, 22.0 | <0.001 | 14.6 | 10.3, 21.0 | ||
| Education | 3,000 | ||||||
| Higher Secondary + | — | — | |||||
| Illiterate | 1.29 | 1.06, 1.58 | 0.010 | ||||
| Primary | 0.89 | 0.69, 1.15 | 0.4 | ||||
| Secondary | 0.75 | 0.58, 0.97 | 0.031 | ||||
| BMI | 2,922 | 1.12 | 1.09, 1.14 | <0.001 | 1.11 | 1.09, 1.13 | <0.001 |
| LDL | 3,000 | 1.01 | 1.00, 1.01 | <0.001 | 1.00 | 1.00, 1.00 | 0.7 |
| Smoking | 3,000 | 0.8 | |||||
| No | — | — | — | — | |||
| Yes | 1.27 | 0.97, 1.65 | 0.080 | 1.03 | 0.77, 1.38 | ||
| Physical_Inactivity | 3,000 | ||||||
| No | — | — | |||||
| Yes | 1.05 | 0.86, 1.28 | 0.6 | ||||
| 1 OR = Odds Ratio, CI = Confidence Interval | |||||||
tbl_strata() for stratified tables
df |>
mutate(Raised_BP = if_else(Raised_BP == 1, "Raised", "Normal")) |>
tbl_strata(
strata = District,
~tbl_summary(.x, by = Raised_BP,
percent = "row",
missing = "no",
include = c(Age_Group, Gender),
digits = list(all_categorical() ~ 1),
statistic = list(all_categorical() ~ "{p}")) |>
modify_header(all_stat_cols() ~ "**{level}**")
)| Characteristic | Balaghat | Bhopal | Damoh | Dhar | Dindori | Hoshangabad | Ratlam | Satna | Sheopur | Shivpuri | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Normal1 | Raised1 | Normal1 | Raised1 | Normal1 | Raised1 | Normal1 | Raised1 | Normal1 | Raised1 | Normal1 | Raised1 | Normal1 | Raised1 | Normal1 | Raised1 | Normal1 | Raised1 | Normal1 | Raised1 | |
| Age_Group | ||||||||||||||||||||
| 18-30 | 89.5 | 10.5 | 91.8 | 8.2 | 93.3 | 6.7 | 87.5 | 12.5 | 97.0 | 3.0 | 93.8 | 6.2 | 93.8 | 6.2 | 90.7 | 9.3 | 93.9 | 6.1 | 96.3 | 3.7 |
| 30-44 | 74.2 | 25.8 | 77.5 | 22.5 | 89.8 | 10.2 | 68.0 | 32.0 | 78.7 | 21.3 | 90.2 | 9.8 | 76.8 | 23.2 | 84.8 | 15.2 | 81.8 | 18.2 | 76.5 | 23.5 |
| 44-59 | 60.9 | 39.1 | 58.0 | 42.0 | 60.0 | 40.0 | 59.5 | 40.5 | 63.4 | 36.6 | 64.3 | 35.7 | 69.2 | 30.8 | 68.9 | 31.1 | 35.0 | 65.0 | 61.0 | 39.0 |
| 59-69 | 37.7 | 62.3 | 26.8 | 73.2 | 44.0 | 56.0 | 34.2 | 65.8 | 40.0 | 60.0 | 46.2 | 53.8 | 63.4 | 36.6 | 60.3 | 39.7 | 44.4 | 55.6 | 33.3 | 66.7 |
| Gender | ||||||||||||||||||||
| Men | 67.2 | 32.8 | 69.9 | 30.1 | 87.1 | 12.9 | 63.2 | 36.8 | 66.7 | 33.3 | 78.7 | 21.3 | 73.0 | 27.0 | 79.0 | 21.0 | 71.1 | 28.9 | 62.5 | 37.5 |
| Women | 65.5 | 34.5 | 69.0 | 31.0 | 69.6 | 30.4 | 71.3 | 28.7 | 76.3 | 23.7 | 76.6 | 23.4 | 81.3 | 18.7 | 78.6 | 21.4 | 71.4 | 28.6 | 74.8 | 25.2 |
| 1 % | ||||||||||||||||||||
In Closing
{gtsummary} website
Package Authors/Contributors
Daniel D. Sjoberg
Michael Curry
Joseph Larmarange
Jessica Lavery
Karissa Whiting
Emily C. Zabor
Xing Bai
Esther Drill
Jessica Flynn
Margie Hannum
Stephanie Lobaugh
Shannon Pileggi
Amy Tin
Gustavo Zapata Wainberg
Other Contributors
@ablack3, @ABorakati, @aghaynes, @ahinton-mmc, @aito123, @akarsteve, @akefley, @albertostefanelli, @alexis-catherine, @amygimma, @anaavu, @andrader, @angelgar, @arbet003, @arnmayer, @aspina7, @asshah4, @awcm0n, @barthelmes, @bcjaeger, @BeauMeche, @benediktclaus, @berg-michael, @bhattmaulik, @BioYork, @brachem-christian, @bwiernik, @bx259, @calebasaraba, @CarolineXGao, @ChongTienGoh, @Chris-M-P, @chrisleitzinger, @cjprobst, @clmawhorter, @CodieMonster, @coeus-analytics, @coreysparks, @ctlamb, @davidgohel, @davidkane9, @dax44, @dchiu911, @ddsjoberg, @DeFilippis, @denis-or, @dereksonderegger, @dieuv0, @discoleo, @djbirke, @dmenne, @ElfatihHasabo, @emilyvertosick, @ercbk, @erikvona, @eweisbrod, @feizhadj, @fh-jsnider, @ge-generation, @ghost, @gjones1219, @gorkang, @GuiMarthe, @hass91, @HichemLa, @hughjonesd, @iaingallagher, @ilyamusabirov, @IndrajeetPatil, @IsadoraBM, @j-tamad, @jalavery, @jeanmanguy, @jemus42, @jenifav, @jennybc, @JeremyPasco, @JesseRop, @jflynn264, @jjallaire, @jmbarajas, @jmbarbone, @JoanneF1229, @joelgautschi, @jojosgithub, @JonGretar, @jordan49er, @jthomasmock, @juseer, @jwilliman, @karissawhiting, @kendonB, @kmdono02, @kwakuduahc1, @lamhine, @larmarange, @leejasme, @loukesio, @lspeetluk, @ltin1214, @lucavd, @LuiNov, @maia-sh, @Marsus1972, @matthieu-faron, @mbac, @mdidish, @MelissaAssel, @michaelcurry1123, @mljaniczek, @moleps, @motocci, @msberends, @mvuorre, @myensr, @MyKo101, @oranwutang, @palantre, @Pascal-Schmidt, @pedersebastian, @perlatex, @philsf, @polc1410, @postgres-newbie, @proshano, @raphidoc, @RaviBot, @rich-iannone, @RiversPharmD, @rmgpanw, @roman2023, @ryzhu75, @sachijay, @saifelayan, @sammo3182, @sandhyapc, @sbalci, @sda030, @shannonpileggi, @shengchaohou, @ShixiangWang, @simonpcouch, @slb2240, @slobaugh, @spiralparagon, @StaffanBetner, @Stephonomon, @storopoli, @szimmer, @tamytsujimoto, @TarJae, @themichjam, @THIB20, @tibirkrajc, @tjmeyers, @tldrcharlene, @tormodb, @toshifumikuroda, @UAB-BST-680, @uakimix, @uriahf, @Valja64, @vvm02, @xkcococo, @yonicd, @yoursdearboy, @zabore, @zachariae, @zaddyzad, @zeyunlu, @zhengnow, @zlkrvsm, @zongell-star, and @Zoulf001.
Thank you
![]()
[Public Health Data Tabulation with {gtsummary})